Most teams discover runaway agent costs during a Friday deploy, not from the dashboard they expected to catch them. Working across different tech companies, we have seen three patterns repeat: cost-per-success quietly rising while prompts look "fine," tool-call latency hiding behind successful 200s, and brittle retrieval chains where stale context drives confident nonsense. Recent industry coverage argues that classic observability was built for human operators, yet agent workloads demand different data, retention, and economics, a point TechRadar laid out clearly in late May 2026 in its piece on how observability for agents needs new primitives. From our experience in the startup ecosystem, the right agent-focused visibility can pay for itself in a single incident.
By 2028, 50 percent of GenAI deployments will invest in LLM observability, up from 15 percent today, according to a March 30, 2026 Gartner press release. In this guide, you will learn where each tool fits, how they differ on data model and deployment, and what to pilot first to cut spend and incident time.
Visibe AI
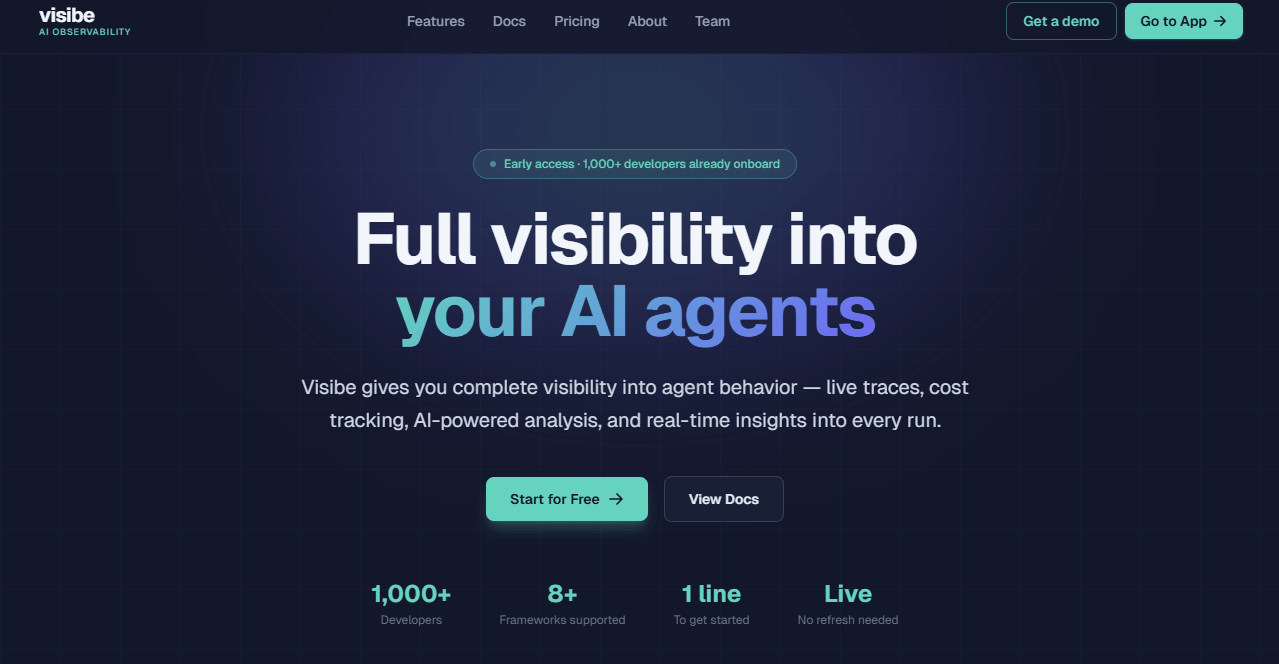
Live traces, cost tracking, and real-time visibility into AI agent behavior, per vendor documentation. Focus is quick, one-line instrumentation and live, no-refresh trace streaming.
Best for: Product teams that want fast setup, live traces, and cost visibility without heavy config.
Key Features:
- Live step and tool-call tracing with real-time dashboards, per vendor documentation
- Cost tracking by agent and model with spend surfacing, per vendor documentation
- One-line SDK instrumentation across Python and Node, per vendor documentation
- AI-assisted trace analysis to summarize hotspots and waste, per vendor documentation
Why we like it: Setup is fast for small teams, and the live view helps catch retry loops or tool thrashing before bills spike.
Notable Limitations:
- Limited independent third-party reviews as of June 10, 2026, so plan a proof-of-value pilot
- On-prem or air-gapped options are not documented publicly
- Advanced governance and auditor-grade workflows are not prominently documented
Pricing: Pricing not publicly available. The site advertises "Start for Free," confirm free trial versus free tier and retention limits directly with the vendor.
Observal
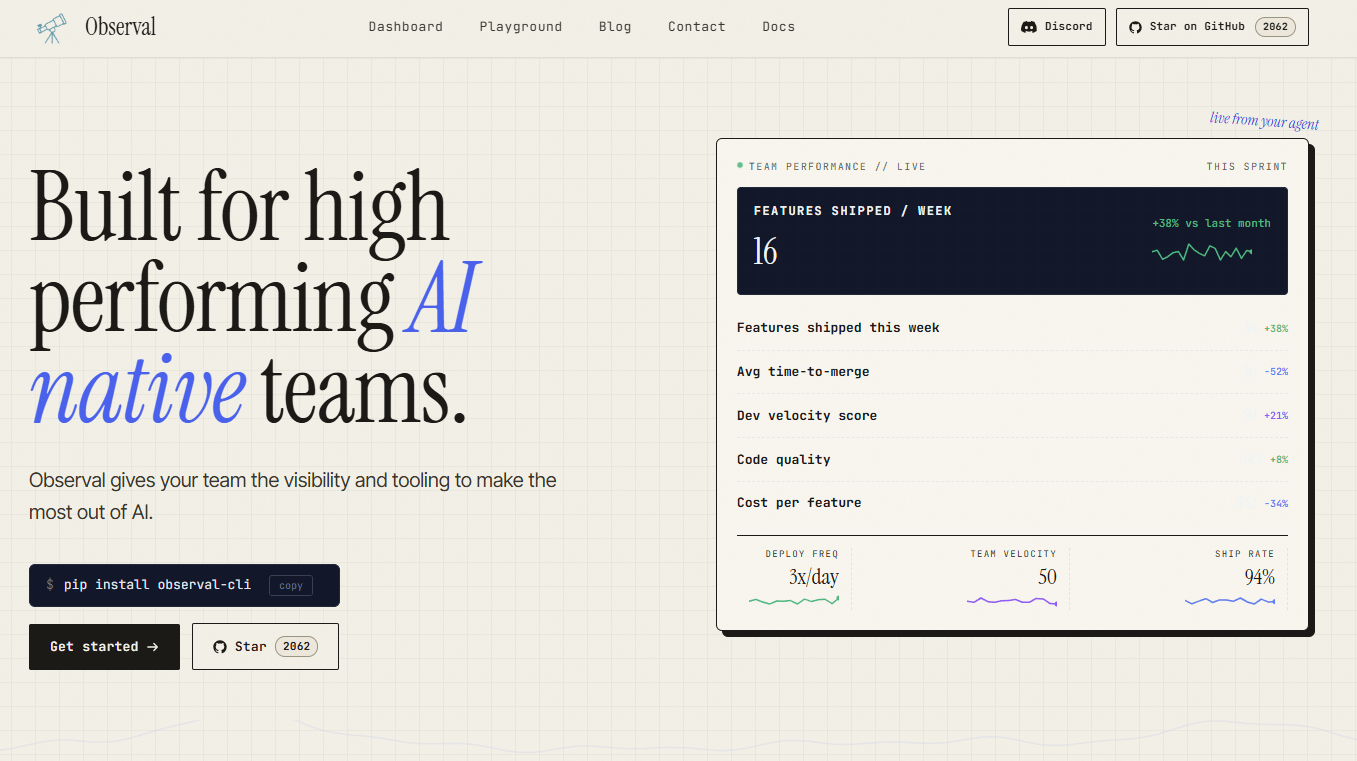
Open-source, self-hosted AI agent registry and observability platform focused on coding agents, per project documentation. Ships with live tracing plus an installable agent catalog.
Best for: Engineering orgs that prefer self-hosted control, are comfortable running open-source stacks, and want an agent registry plus tracing.
Key Features:
- Agent registry to browse and install curated coding agents, per project documentation
- Live tracing of tokens, tool calls, and sessions, per project documentation
- Executive dashboards for cost and velocity insights, per project documentation
- Self-hosted deployment under AGPL-3.0, per project documentation
Why we like it: The registry plus tracing combination can standardize agent adoption across engineering teams without SaaS data flow.
Notable Limitations:
- Self-hosting adds operational overhead for upgrades, security, and backups
- Early community footprint, so enterprise references and integrations may be limited
- Air-gapped installs will require internal packaging and governance effort
Pricing: Open source, self-hosted. No license fees, but expect infra and maintenance costs.
Tracium
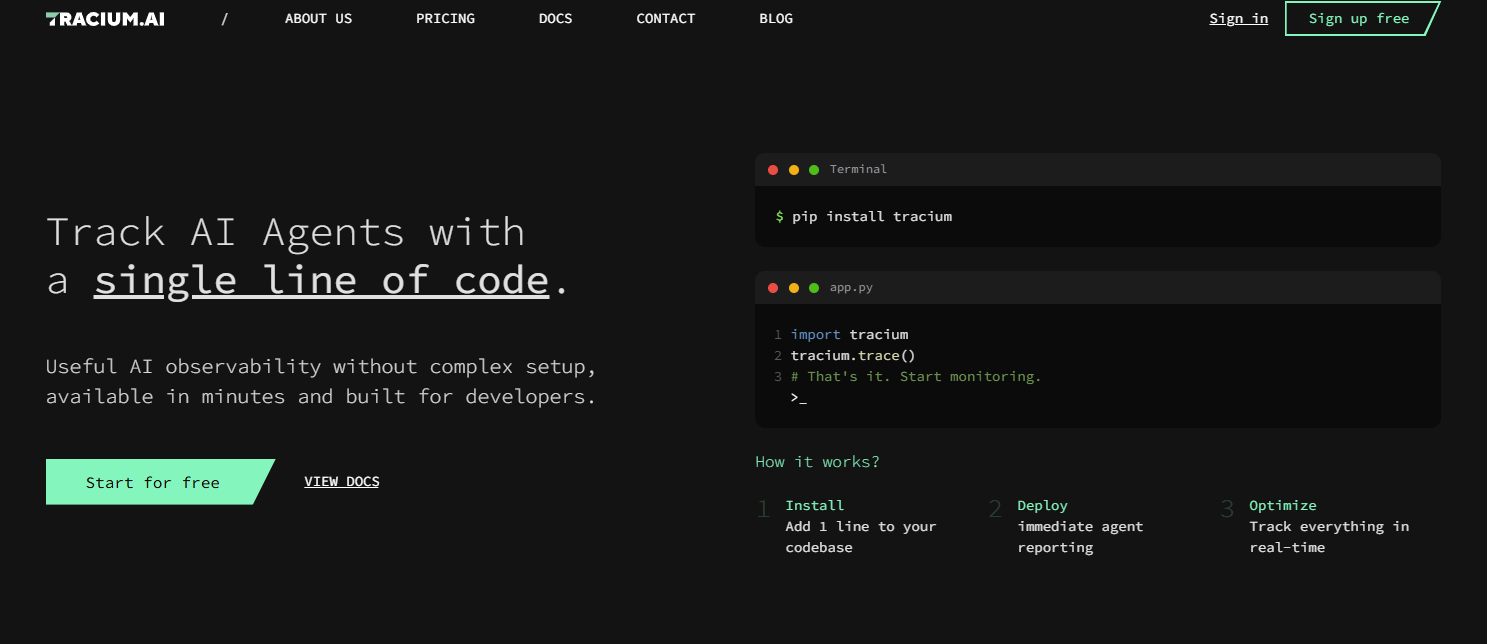
Developer-first AI observability with one-line setup to trace requests, costs, errors, and agent behavior, per vendor documentation. Emphasis on fast debugging and drift monitoring.
Best for: Developers who want to start tracing and cost monitoring within minutes, with basic alerting and side-by-side comparisons.
Key Features:
- Token, cost, and latency tracking by model, agent, and workflow, per vendor documentation
- Failure capture with replay across model calls, tools, and steps, per vendor documentation
- Drift and A/B comparison for prompts and models, per vendor documentation
- One-line SDK setup across common LLM frameworks, per vendor documentation
Why we like it: Clear path to value for small teams, with practical features like run replay and prompt comparison.
Notable Limitations:
- Free plan retention is short for production forensics
- Limited independent enterprise reviews as of June 10, 2026
- Advanced compliance controls may require additional tooling
Pricing: Per vendor site as of June 10, 2026, Free at $0 per month includes 5,000 traces and 7-day retention, Developer at $29 per month raises limits and adds alerts and drift monitoring. Confirm current tiers before purchase.
AnoSys.AI
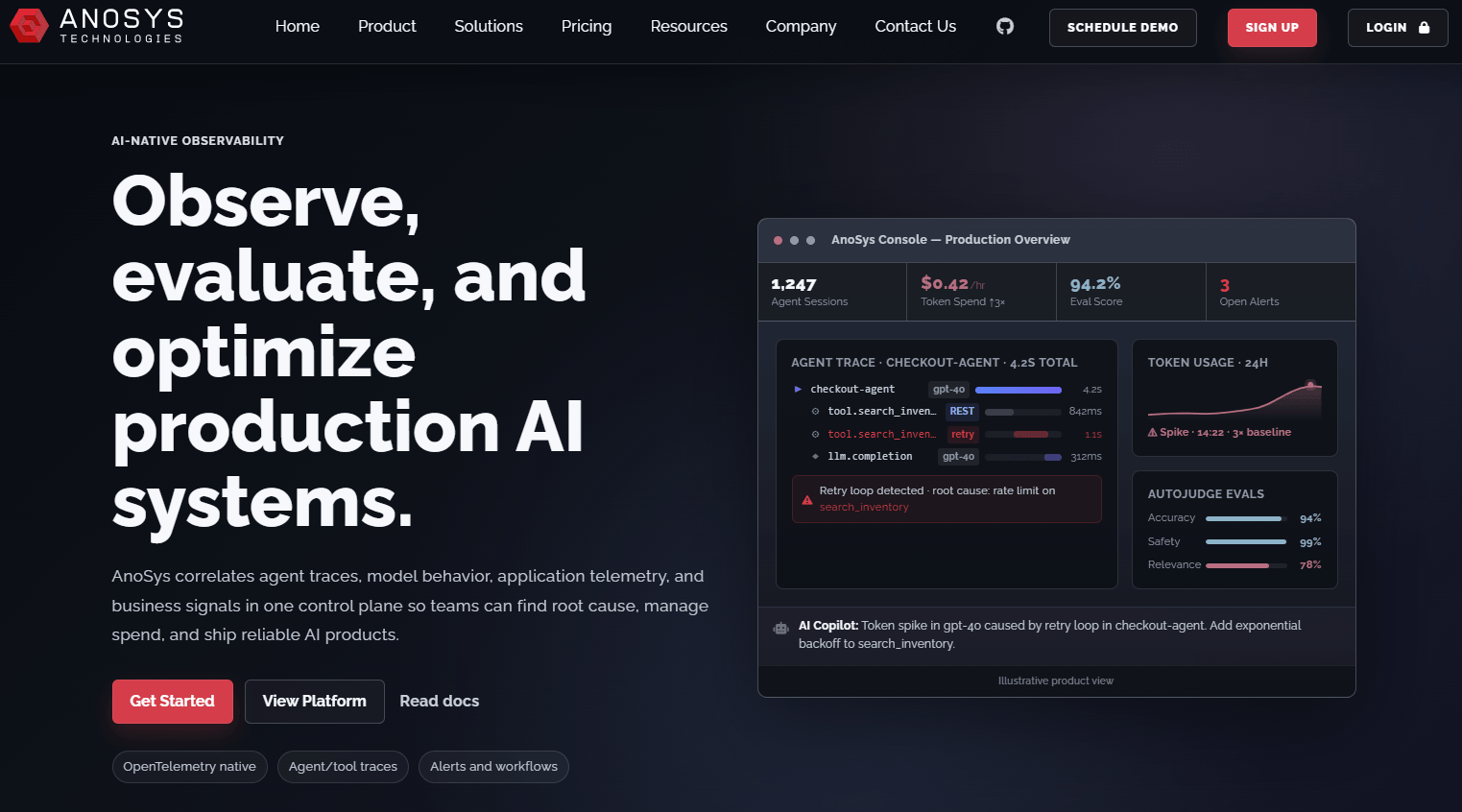
Observability control plane that correlates agent traces, LLM behavior, infrastructure telemetry, and business signals in one place, per vendor documentation. OpenTelemetry-native ingestion with evaluation hooks.
Best for: Teams that want agent traces correlated with logs, metrics, and business KPIs for end-to-end root cause and spend optimization.
Key Features:
- Correlation across agent runs, model behavior, infra telemetry, and KPIs, per vendor documentation
- OTLP ingestion and SDKs for agents and apps, per vendor documentation
- Built-in evaluation pipelines and anomaly detection, per vendor documentation
- Long-retention options for historical analysis, per vendor documentation
Why we like it: The "control plane" approach connects agent failures to upstream dependencies and cost anomalies, which shortens time to actionable fixes.
Notable Limitations:
- Primarily cloud deployment documented, on-prem or air-gapped options not prominently published
- Implementation depth means a steeper initial setup than "just traces" tools
- Independent third-party reviews are limited as of June 10, 2026
Pricing: Pricing not publicly available. Per documentation, usage is based on data volume rather than seats. Contact vendor for a custom quote.
AI Agent Observability Tools Comparison: Quick Overview
| Tool | Best For | Pricing Model | Highlights |
|---|---|---|---|
| Visibe AI | Fast live traces and cost surfacing for small to mid teams | Not publicly listed, "Start for Free" advertised | One-line SDK, live stream tracing, AI-assisted analysis |
| Observal | Self-hosted teams that want a registry plus tracing | Open source, AGPL-3.0 | Agent registry, live tracing, executive dashboards |
| Tracium | Developer-first tracing, costs, drift with quick setup | Subscription tiers with free tier | Replay failures, prompt comparison, drift monitoring |
| AnoSys.AI | Correlated agent, infra, and business signals | Usage based on data volume, trial noted | OTLP-native, eval pipelines, long retention options |
AI Agent Observability Platform Comparison: Key Features at a Glance
| Tool | Live Agent Tracing | Cost per Run/Agent | Evaluation Hooks |
|---|---|---|---|
| Visibe AI | Yes | Yes | AI summarize of traces |
| Observal | Yes | Yes | Basic insights, open source extensibility |
| Tracium | Yes | Yes | Drift and A/B tools |
| AnoSys.AI | Yes | Yes | Built-in evals and anomaly detection |
AI Agent Observability Deployment Options
| Tool | Cloud API | On-Premise / Air-Gapped | Integration Complexity |
|---|---|---|---|
| Visibe AI | Yes | Not documented | One-line SDK, fast start |
| Observal | Self-hosted | Yes, possible with self host | Moderate, infra ownership |
| Tracium | Yes | Not documented | One-line SDK, light config |
| AnoSys.AI | Yes | Not documented | OTLP plus app SDKs, broader setup |
AI Agent Observability Strategic Decision Framework
| Critical Question | Why It Matters | What to Evaluate | Red Flags |
|---|---|---|---|
| Do you need registry plus tracing, or tracing only | Reduces tool sprawl and speeds adoption | Built-in registry, versioning, run reviews | No standardized way to register and govern agents |
| How will you manage cost per success | Agent loops and retries can sink ROI | Spend per run, anomaly alerts, token accounting | Only total model spend, no per-run attribution |
| Can you correlate agent failures to upstream systems | Agents fail due to data, tools, or infra | OTLP support, infra metrics, KPIs | Isolated traces without infra context |
| What retention window do you need | Short windows miss seasonality and rare failures | 90 to 180 days for production forensics | 7 to 14 days only for full fidelity |
| Do you need self-hosted or air gapped | Compliance and data gravity drive deployment | Open-source or private cloud options | SaaS-only with limited data controls |
AI Agent Observability Solutions Comparison: Pricing and Capabilities Overview
| Organization Size | Recommended Setup | Monthly Cost | Annual Investment |
|---|---|---|---|
| Seed to Series A startup | Tracium free or developer tier to establish baselines, add Visibe AI for live incident triage | From $0 to low double digits per developer | Minimal to low thousands |
| Mid-market product teams | Visibe AI or Tracium plus Observal self-hosted for coding agents registry and run reviews | Varies by traces and infra | Mid to high five figures, infra included |
| Enterprise with compliance needs | AnoSys.AI for correlated signals and eval pipelines, optional Observal for controlled agent distribution | Custom, usage based | Six figures depending on data volume |
Problems & Solutions
Problem: Cost spikes from retry loops, long contexts, and hidden cascades
Why it happens: Traditional observability pricing and retention patterns were optimized for humans, not machines that run continuous analysis, which can bury the signals needed to catch agent waste early.
Solutions by tool:
- Visibe AI - live per-run cost and AI summaries surface hotspots quickly, per documentation.
- Tracium - token and latency tracking by agent with drift detection helps flag rising costs, per documentation.
- AnoSys.AI - anomaly detection with long retention ties token spikes to upstream dependencies, per documentation.
- Observal - executive dashboards provide cost intelligence for coding agents while keeping data self-hosted, per project docs.
Problem: Hard-to-reproduce agent failures across multi-step tool use
Why it happens: Evidence shows error propagation across agent steps is not temporal, so replay needs dependency graphs and execution provenance, not just waterfalls. Research on graph-guided failure tracing and a 2026 survey on evidence tracing and execution provenance in agents reinforce this point.
Solutions by tool:
- Tracium - replay of failures across model calls and tools gets developers to minimal repro fast, per documentation.
- AnoSys.AI - correlates traces with KPIs and infra metrics to isolate root cause beyond the LLM span, per documentation.
- Visibe AI - live step-level tracing and AI summarization highlight what to fix now, per documentation.
- Observal - open-source model lets teams extend trace schemas to capture tool parameters and dependencies.
Problem: Execs need adoption, ROI, and risk summaries, not raw spans
Why it matters: Analysts forecast a rapid shift toward explainable AI and observability investments as deployments scale, so leaders will ask for auditability and ROI views, not just traces.
Solutions by tool:
- Observal - executive dashboards for cost intelligence and velocity metrics, per project docs.
- AnoSys.AI - built-in eval pipelines and long retention produce trend and governance views, per documentation.
- Visibe AI and Tracium - cost and drift signals that can roll up into executive scorecards with light work.
Problem: Choosing in a crowded and shifting market
What to know: Observability vendors and AIOps platforms are converging, and analysts highlight rapid evolution in observability platforms, making selection about data foundations and governance as much as UI. Gartner's research on observability platforms and IDC commentary on the European observability market both underscore this trend.
Solution: Start with a pilot that measures cost per success and time to resolution, keep data retention long enough to analyze seasonality, and prefer platforms that can correlate agent traces with infra and business signals.
The Bottom Line
Every agent team eventually needs more than logs and LLM call histories - they need run-level cost, dependency-aware traces, and a path to auditor-grade evidence. If you want fast time to value, start with Tracium or Visibe AI to stop the bleeding on spend and debugging time, then add AnoSys.AI when you are ready to correlate agents with infra and business signals. If you prefer absolute control, Observal's self-hosted registry plus tracing offers a community-driven path. The direction of travel is clear, as recent analyst research points to rising investments in LLM observability as deployments mature, and industry coverage underscores that agent workloads need different data and economics than human-first observability stacks.


