You think you know your model's quality until a production prompt drifts, a provider updates a model family, or a retrieval index goes stale. Working across different tech companies, we have seen the biggest reliability gaps show up in CI pipelines rather than glossy demo decks. From our experience in the startup ecosystem, three patterns keep teams out of trouble: regression tests on golden datasets, online evaluations against real traffic, and human review queues for ambiguous cases. The stakes are rising fast, with worldwide generative AI spending projected to reach $644 billion in 2025, according to Gartner's March 31, 2025 forecast.
The short list below focuses on four options that consistently delivered strong coverage of LLM evaluation and benchmarking, and that span different approaches - from workflow-level observability to crowd-sourced pairwise ranking. You will learn which tool to pick for offline vs online evaluations, how to combine "LLM-as-a-judge" with human review, and where each platform's pricing and deployment model fits different team sizes.
LangSmith
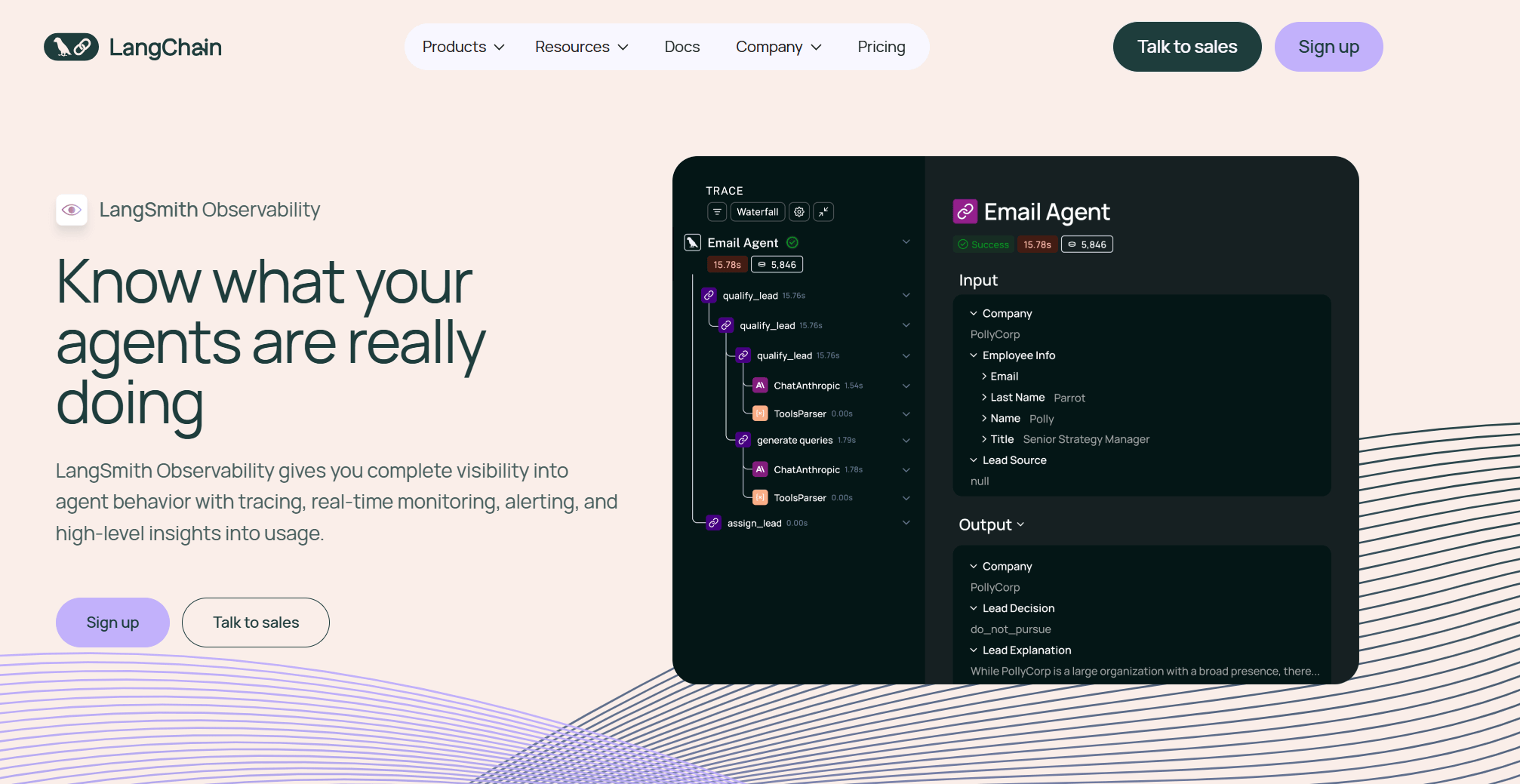
Platform for tracing, observability, and evaluation across LLM and agent workflows. Supports offline and online evaluations, prompt experiments, and human annotation queues.
- Best for: Product teams that want end-to-end tracing plus continuous offline and online evaluations for agentic apps.
- Key Features: Dataset-based offline evals, online evals on live traffic, human annotation queues, OpenTelemetry support, CI-friendly experiments.
- Why we like it: Strong "one place to debug, test, and compare" workflow, plus standards-based telemetry that plays well with existing observability stacks.
- Notable Limitations: Community feedback has flagged occasional UI instability and framework breaking changes; LLM-as-judge metrics require bias mitigation for high-stakes use.
- Pricing: Free developer tier and team pricing reported publicly by third-party writeups, including a Plus plan at $39 per seat with included trace allotments and pay-as-you-go overages, see summaries from Artic Sledge and AgentsAPIs. Confirm current rates directly with the vendor.
DeepEval (Confident AI)
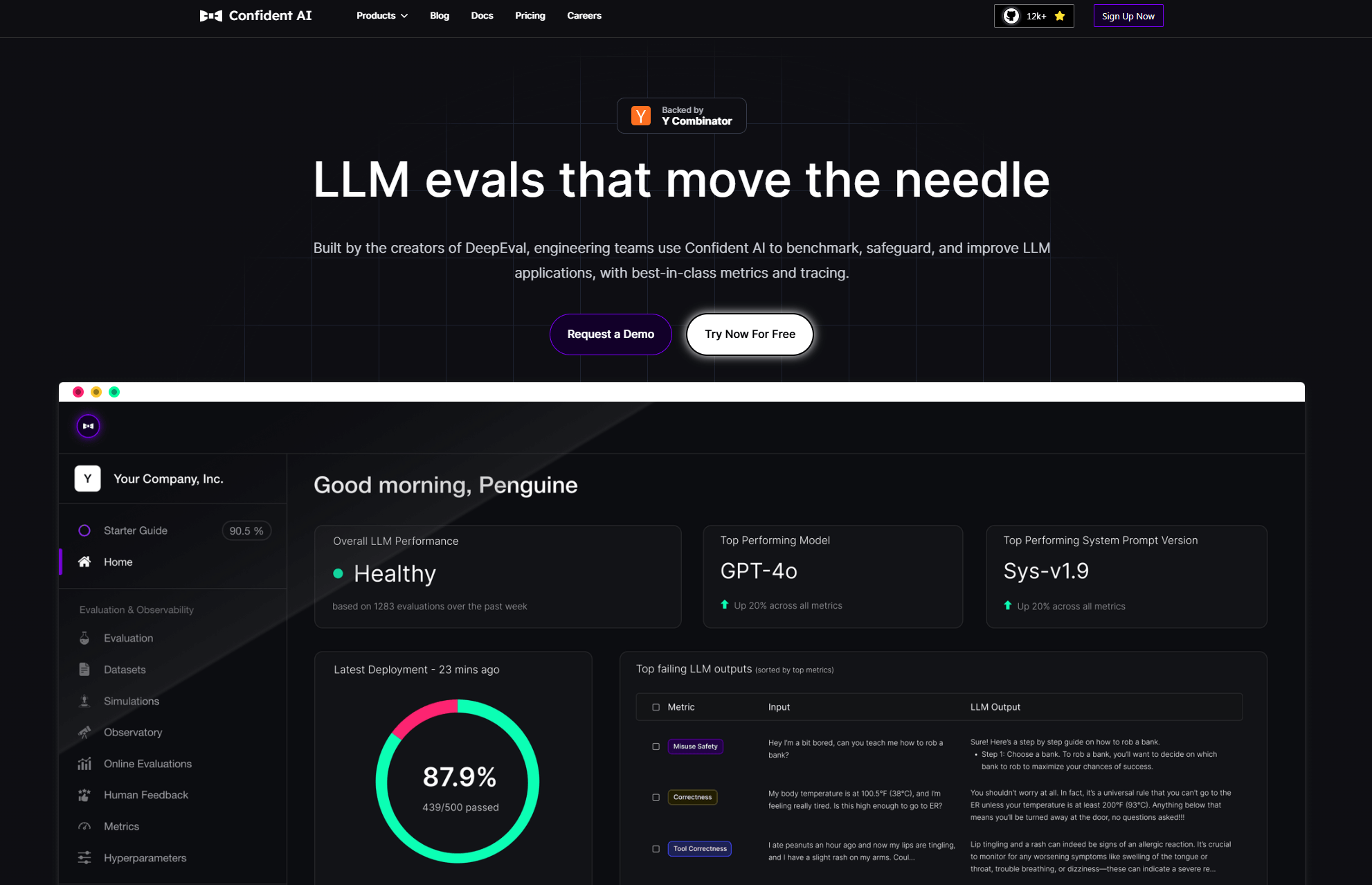
Open-source LLM evaluation framework with a hosted platform for dataset curation, monitoring, and reporting. Ships many ready-to-run metrics and supports custom evaluators.
- Best for: Teams that want a pytest-like local evaluation workflow with an optional cloud layer for reports, datasets, and online evals.
- Key Features: 40+ metrics including RAG faithfulness and answer relevancy, unit and regression testing, safety red teaming, CI/CD integration, dataset curation in the hosted platform.
- Why we like it: Fast path from local tests to shareable cloud reports, with a broad metric library that saves engineering time.
- Notable Limitations: Heavy use of LLM-as-judge brings known bias risks, and smaller teams report mixed views on paying for managed features early in the lifecycle.
- Pricing: Third-party listings show a Free tier, a Starter plan "from $19.99 per user per month," and Premium at $79.99, see Creati.ai and ToolMesh. Treat as indicative, confirm details directly.
Autoevals (Braintrust)
Open-source library and platform for automatic evaluation using LLM-as-a-judge, heuristics, and statistical methods. Optional managed observability with scoring and usage-based quotas.
- Best for: Engineers who want quick, scriptable evals in Python or TypeScript, then a managed workspace to log runs, compare prompts, and monitor production.
- Key Features: Model-graded scoring, BLEU and Levenshtein heuristics, RAG metrics, custom evaluators, optional AI proxy integration, logging and scoring in the hosted platform.
- Why we like it: Easy to start with model-graded checks, then graduate to a dashboard that tracks scores over time across datasets and versions.
- Notable Limitations: Defaults often assume OpenAI-compatible APIs, which teams should review when standardizing providers; like all LLM-judge systems, bias controls matter.
- Pricing: Third-party pages reflect a Free tier and Pro at $249 per month with quotas for "processed data" and "scores," see AI Tech Suite and Creati.ai. Verify on the public pricing page before purchase.
LMArena
Crowd-sourced platform comparing LLM responses via anonymous pairwise votes, with Elo-style rankings and public leaderboards.
- Best for: Anyone who wants a fast pulse on relative model quality based on large-scale human preference votes.
- Key Features: Anonymous A/B battles, pairwise voting, public leaderboards, new "Search Arena" for RAG-style tasks, growing multimodal coverage.
- Why we like it: Real-world prompts and scale, with transparent methods and community data releases that complement lab benchmarks.
- Notable Limitations: Crowd preference data may not represent your domain, and Elo-style rankings have known stability caveats.
- Pricing: Free public site at time of writing, no paid tiers listed in public coverage, see background from LMSYS and reporting by Business Insider.
LLM Evaluation & Benchmarking Tools Comparison: Quick Overview
| Tool | Best For | Pricing Model | Free Option |
|---|---|---|---|
| LangSmith | Teams shipping agent workflows that need tracing plus evals | Seat plus usage for traces | Yes |
| DeepEval (Confident AI) | Local evals with optional hosted datasets and reports | Freemium per user | Yes |
| Autoevals (Braintrust) | Scriptable model-graded checks with managed logging | Freemium plus Pro | Yes |
| LMArena | Public pairwise benchmarking and quick pulse checks | Free community site | Yes |
LLM Evaluation & Benchmarking Platform Comparison: Key Features at a Glance
| Tool | Offline and Online Evals | Human Review | Open Standards/OTel |
|---|---|---|---|
| LangSmith | Yes | Yes | Yes, OpenTelemetry |
| DeepEval (Confident AI) | Yes | Yes | OSS framework, standard CI tools |
| Autoevals (Braintrust) | Yes | Limited built-ins, extensible | API, multi-provider proxy |
| LMArena | Online only, community traffic | No, crowd votes instead | Public methods, Elo-style ranking |
LLM Evaluation & Benchmarking Deployment Options
| Tool | Cloud API | On-Premise | Integration Complexity |
|---|---|---|---|
| LangSmith | Yes | Enterprise self-host | Low to Medium for LangChain or OTel |
| DeepEval (Confident AI) | Yes | Self-host available | Low for OSS, Medium for hosted |
| Autoevals (Braintrust) | Yes | Enterprise option | Low in code, Medium for managed |
| LMArena | Yes | No | Very Low, web use only |
LLM Evaluation & Benchmarking Strategic Decision Framework
| Critical Question | Why It Matters | What to Evaluate |
|---|---|---|
| Do you need online evaluation on live traffic or only offline tests? | Online evals catch regressions fast when models or prompts change | Support for streaming evals, drift dashboards, alerting |
| How will you mitigate LLM-judge bias? | LLM-as-judge can skew scores through position and verbosity bias | Order randomization, rubric shuffling, multi-judge ensembles, human spot checks |
| Do you require on-prem or VPC-only deployments? | Regulated data and IP constraints | Self-host docs, SOC 2, data residency options |
| Will non-ML stakeholders review outputs? | SMEs often decide "good enough" | Annotation queues, shareable reports, diff views |
LLM Evaluation & Benchmarking Solutions Comparison: Pricing & Capabilities Overview
| Organization Size | Recommended Setup | Monthly Cost |
|---|---|---|
| Solo developer | DeepEval locally, LMArena for quick checks; LangSmith Free for tracing | $0 using free tiers |
| 5-person startup team | LangSmith Plus for shared evals, Autoevals with Braintrust Free or Pro for scoring dashboards | LangSmith 5 seats approximately $195, Braintrust Pro $249, total approximately $444, based on third-party listings from AgentsAPIs and AI Tech Suite |
| Mid-size product org | LangSmith Plus or Enterprise, Confident AI Premium for no-code workflows, LMArena to track public standing | Pricing not publicly available for enterprise tiers. Contact vendors. |
| Regulated enterprise | Self-host LangSmith and Confident AI, limit data egress, add human review program | Pricing not publicly available. Contracted terms vary. |
Problems & Solutions
-
Problem: LLM-as-judge bias can mis-rank outputs, especially with order, verbosity, and sentiment effects.
Solution: All four tools allow bias-aware setups, and you should randomize order, use multiple judges, and add human review on a sample. Research finds measurable judge bias and offers mitigation guidance, see a 2024 survey on LLM-as-a-Judge reliability (arXiv) and bias quantification work that catalogues 12 bias types including position and verbosity (Notre Dame summary of CALM and the supporting paper). LMArena's Elo-style approach is transparent, but ranking stability needs care per independent analyses of Elo under misspecification (arXiv). -
Problem: Model or prompt updates cause silent regressions after release.
Solution: Adopt continuous evaluation in CI and online traffic. Public writeups show the market shifting from DIY POCs to off-the-shelf GenAI capabilities in 2025, making regression control key for CIOs (Gartner IT spending outlook, Oct 23, 2024). LangSmith, DeepEval's hosted platform, and Braintrust all support dataset-based tests and version comparisons, while LMArena offers a community pulse when major model families change. -
Problem: You need real users' preferences to inform model selection.
Solution: Use LMArena's anonymized pairwise voting and leaderboard methods to see how your shortlisted models perform on community prompts. The platform has grown from early releases to millions of votes and multi-modal coverage (LMSYS overview, plus recent reporting on growth and modality expansion by Business Insider). For enterprise-specific data, mirror the approach internally with dataset curation in Confident AI or LangSmith. -
Problem: Picking a tool that fits budget constraints.
Solution: Use free tiers to validate fit, then scale gradually. Representative list prices from independent pages show LangSmith's Plus tier at $39 per seat and included trace allotments (AgentsAPIs), Confident AI's Starter from $19.99 and Premium at $79.99 (Creati.ai), and Braintrust's Pro at $249 per month with quotas (AI Tech Suite). Always confirm current pricing before purchase.
Bottom Line: Pick the Right Mix for Your Stage
Most teams discover evaluation gaps during production incidents, not during model bake-offs. The fastest path to reliability is a blend of offline datasets, online evals, and real human feedback, plus periodic reality checks from a public benchmark like LMArena. The market is moving quickly toward packaged GenAI capabilities, with spending surging in 2025 (Gartner) and a competitive vendor landscape that keeps adding features (S&P Global). Start with the free tiers, stand up CI-backed evals in week one, and add human review for the last mile. That approach saves time and money while giving your team the confidence to ship.


