Most teams discover that their LLMs leak sensitive data during real multi-turn user conversations, not during internal QA. Across different tech companies in 2026, the same failure patterns keep surfacing: prompt injection through RAG connectors, jailbreaks that bypass policy during agent tool use, and indirect instructions hidden inside emails or documents. Breach economics continue to raise the stakes, with the global average cost of a data breach now exceeding four million dollars and a majority of organizations reporting at least one AI related security incident tied to weak access controls or insufficient testing. The purpose of this guide is to help teams identify these risks early through structured red teaming, rather than reacting after an incident reaches production.
Giskard Continuous Red Teaming
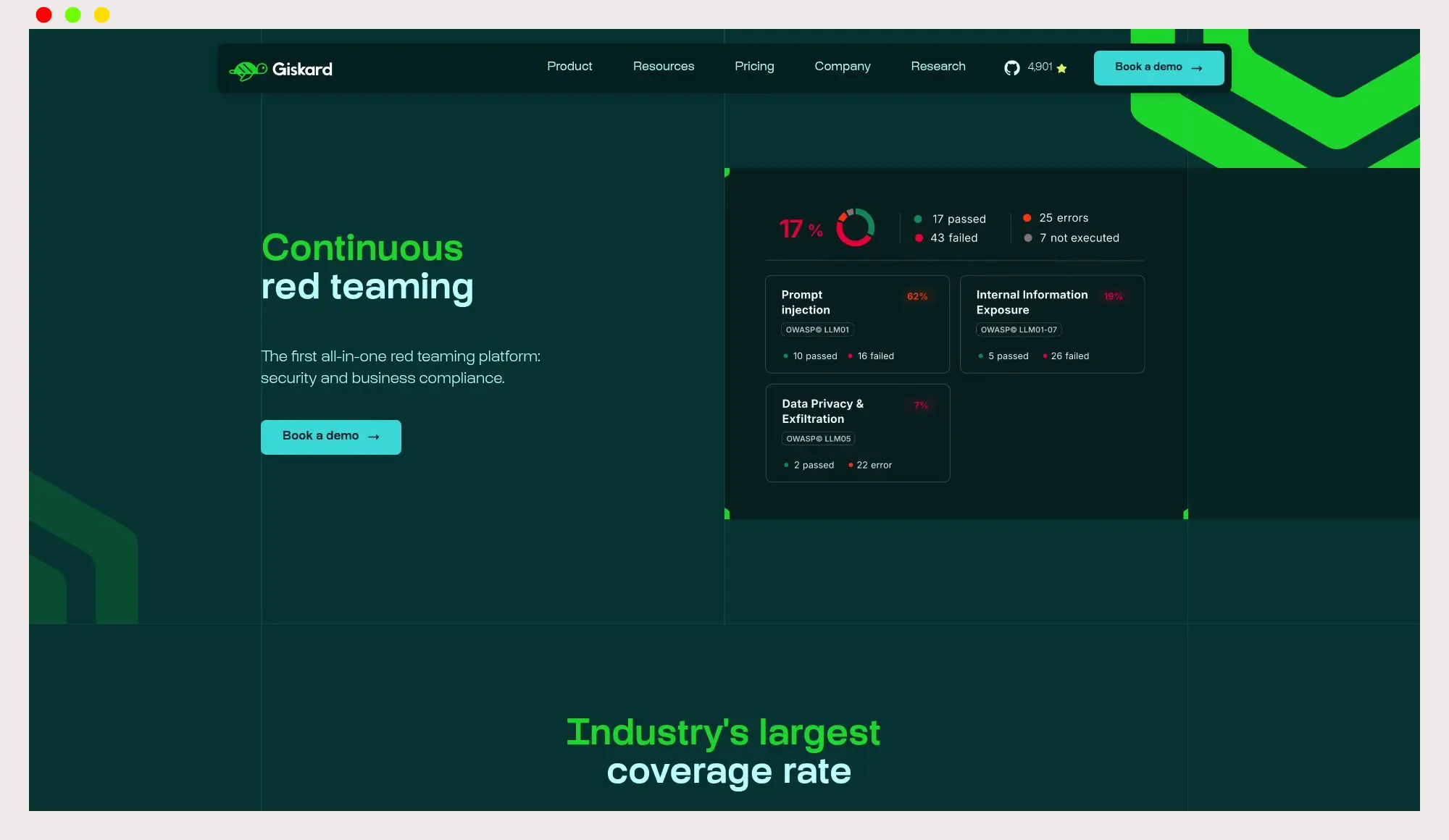
Automated, ongoing adversarial testing focused on LLM apps and agents. Designed to catch regressions and newly emerging jailbreak patterns across multi‑turn interactions.
According to vendor documentation.
Best for: Teams that want continuous adversarial evaluation tied to model and RAG changes.
Key Features:
- Continuous multi‑turn attack generation and replay across evolving datasets, per vendor documentation.
- Test case enrichment with new security patterns from external signals, per vendor documentation.
- Integrates with model evaluation workflows, and is cited among AI testing platforms in third‑party coverage of the space, such as TechCrunch’s testing market overview.
Why we like it: From my experience in the startup ecosystem, continuous testing catches policy drift when you update prompts, plug‑ins, or knowledge bases. Treat it like CI for red teaming.
Notable Limitations:
- Continuous service availability and exact deployment modes are not fully detailed in public third‑party sources, so buyers should request an architecture brief.
- Smaller vendor footprint compared with large security firms, based on public funding and ecosystem mentions in third‑party articles like TechCrunch.
Pricing: Pricing not publicly available. Contact the vendor for a custom quote.
Lakera Red
AI‑native red teaming focused on pre‑deployment assessments with risk‑based prioritization and expert guidance.
According to vendor documentation and third‑party news.
Best for: Enterprises needing structured pre‑deployment AI security assessments with a path to runtime controls via Lakera Guard.
Key Features:
- Pre‑deployment posture assessments for LLMs and agents, with runtime enforcement available through Lakera Guard, per coverage in CRN and ITPro.
- Research‑driven detections informed by a large adversarial interaction corpus referenced in acquisition coverage, as noted by ITPro.
- Backed by significant funding momentum prior to acquisition, as reported by TechCrunch.
Why we like it: Risk‑based guidance helps teams prioritize fixes before rollout, which shortens the path to approval and reduces rework.
Notable Limitations:
- Acquisition announced on September 16, 2025 by Check Point, with closing expected in Q4 2025, so packaging and roadmap may change, per ITPro and CRN.
- No public price list and limited independent benchmarks available.
Pricing: Pricing not publicly available. Contact the vendor or, post‑close, Check Point for a custom quote.
Group‑IB AI Red Teaming
Service‑based adversarial testing of GenAI systems aligned to industry frameworks, delivered by an established cybersecurity provider.
According to vendor documentation and third‑party industry news.
Best for: Regulated organizations that prefer a human‑led engagement mapped to standards and enterprise risk.
Key Features:
- Tailored GenAI attack simulations with findings aligned to OWASP LLM Top 10, MITRE ATLAS, ISO 42001, and NIST AI RMF, per vendor documentation.
- Delivery by an experienced red team provider with active industry presence, reflected in recent coverage such as ChannelPro.
- Emphasis on evidence‑based reporting and remediation planning, per vendor documentation.
Why we like it: For boards and auditors, a standards‑mapped service produces artifacts that plug into existing governance and risk processes.
Notable Limitations:
- Service engagements can have lead times and require access to sensitive environments, which extends timelines, a common reality noted in red‑team best practices literature like the NIST AI RMF.
- No public pricing.
Pricing: Pricing not publicly available. Contact Group‑IB for a custom quote.
Microsoft AI Red Teaming Agent (PyRIT)
Open‑source framework that automates multi‑turn adversarial probing and scoring for generative AI targets.
Publicly described by independent coverage.
Best for: Security and ML teams that want a free, scriptable red‑teaming baseline that scales across attack categories.
Key Features:
- Multi‑turn and single‑turn attack strategies with automated scoring across harm categories, as summarized by Redmondmag.
- Targets web services and app‑embedded models, supporting Azure OpenAI, Hugging Face, and custom endpoints, per Redmondmag.
- Memory and reporting for replayability and analysis, per Redmondmag.
Why we like it: After helping startups scale their AI apps, I view PyRIT as the quickest way to baseline defenses and catch obvious jailbreak classes before you pay for services.
Notable Limitations:
- Python version constraints have surfaced in community issues, for example Python 3.13 support gaps referenced in a GitHub discussion (issue thread).
- Automation does not replace expert manual probing, as even independent coverage notes (Redmondmag).
Pricing: Free and open source, per independent coverage in Redmondmag.
AI Red Teaming Tools Comparison: Quick Overview
| Tool | Best For | Pricing Model | Free Option | Highlights |
|---|---|---|---|---|
| Giskard Continuous Red Teaming | Continuous adversarial tests tied to RAG and prompt changes | Enterprise contract | No | Continuous multi‑turn attack generation and replay, per vendor documentation; noted in third‑party market coverage of testing vendors like TechCrunch. |
| Lakera Red | Pre‑deployment security assessment with risk‑based prioritization | Enterprise contract | No | Pre‑deployment focus with a path to runtime controls via Lakera Guard, per CRN. |
| Group‑IB AI Red Teaming | Standards‑mapped, human‑led testing for regulated orgs | Consulting engagement | No | Aligns to OWASP LLM Top 10 and NIST AI RMF, per vendor documentation; active ecosystem presence reported by ChannelPro. |
| Microsoft AI Red Teaming Agent (PyRIT) | Teams wanting a free automation baseline | Open source | Yes | Multi‑turn automation and scoring across harm categories, per Redmondmag. |
AI Red Teaming Platform Comparison: Key Features at a Glance
| Tool | Multi‑turn Attacks | Standards Mapping | Reporting Scorecards |
|---|---|---|---|
| Giskard Continuous Red Teaming | Yes, per vendor documentation | Supports standards‑aligned testing, per vendor documentation | Yes, per vendor documentation |
| Lakera Red | Yes, per third‑party coverage | Yes, via risk‑based guidance, per CRN | Yes, per third‑party coverage |
| Group‑IB AI Red Teaming | Yes, human‑led | Explicitly aligns to OWASP LLM Top 10 and NIST AI RMF, per vendor documentation | Yes, per vendor documentation |
| Microsoft AI Red Teaming Agent (PyRIT) | Yes | Community users map to OWASP categories in practice, see Redmondmag | Exports and logs for analysis, per Redmondmag |
AI Red Teaming Deployment Options
| Tool | Cloud API | On‑Premise | Air‑Gapped | Integration Complexity |
|---|---|---|---|---|
| Giskard Continuous Red Teaming | Yes, via managed service, per vendor documentation | Vendor says it integrates with existing workflows | Depends on setup, request details | Medium |
| Lakera Red | Yes, per third‑party coverage | Not publicly documented, request details | Not publicly documented | Medium |
| Group‑IB AI Red Teaming | N/A, service engagement | Yes, delivered in customer environments | Depends on engagement scope | High, due to scoping and access |
| Microsoft AI Red Teaming Agent (PyRIT) | No, local framework | Yes, runs locally | Yes, if dependencies are met | Medium, scripting required |
AI Red Teaming Strategic Decision Framework
| Critical Question | Why It Matters | What to Evaluate | Red Flags |
|---|---|---|---|
| Can the tool simulate multi‑turn, indirect prompt injection? | Most real attacks are multi‑step and contextual, as highlighted by the OWASP LLM Top 10. | Support for attack chaining, memory, tool‑use probing | Single‑turn only, no memory |
| How are findings mapped to standards? | Speeds sign‑off with security and audit teams aligned to NIST AI RMF. | OWASP LLM Top 10, MITRE ATLAS, ISO 42001 mapping | Free‑form findings with no taxonomy |
| Do you get measurable metrics like Attack Success Rate? | Objective metrics help track drift and remediation impact. | ASR per category, regression dashboards | Only qualitative findings |
| What is the path from assessment to runtime control? | Pre‑deployment fixes must carry into production. | Connections to content filters, policy engines, guardrails | Findings do not map to enforcement |
| How will this scale across models and apps? | Model and app churn is constant. | SDKs, APIs, CI hooks, replay suites | Manual, one‑off testing only |
AI Red Teaming Solutions Comparison: Pricing & Capabilities Overview
| Organization Size | Recommended Setup | Monthly Cost | Annual Investment |
|---|---|---|---|
| Startup | PyRIT for baseline, plus targeted service hours from a provider when needed | PyRIT is free, service rates vary | Pricing not publicly available for services |
| Mid‑market | Giskard continuous testing plus PyRIT baselines | Pricing not publicly available | Pricing not publicly available |
| Enterprise | Lakera Red or Group‑IB engagement for pre‑deployment and governance, PyRIT for CI baselines | Pricing not publicly available | Pricing not publicly available |
Problems & Solutions
-
Problem: Prompt injection and data exfiltration through hidden instructions are now practical in production‑grade systems, as shown by research on attacks like Imprompter and recent case studies on zero‑click injection in assistants (Wired, arXiv case study).
How each tool helps:- PyRIT automates single and multi‑turn jailbreak attempts and scoring to detect these patterns early, according to independent coverage in Redmondmag.
- Lakera Red emphasizes pre‑deployment risk assessments and can be paired with runtime enforcement in Lakera Guard, as reported by CRN.
- Group‑IB runs tailored adversarial tests mapped to OWASP categories like LLM01 Prompt Injection, per vendor documentation and the OWASP Top 10.
- Giskard’s continuous suite surfaces regressions as prompts, agents, or RAG sources change, per vendor documentation.
-
Problem: Multi‑agent logic flaws and insecure tool or plug‑in design increase real‑world risk, a category highlighted in the OWASP LLM Top 10.
How each tool helps:- PyRIT supports multi‑turn strategies, helping expose tool‑chain misuse, per Redmondmag.
- Group‑IB service aligns findings to standards like MITRE ATLAS and provides remediation plans tied to business risk, per vendor documentation.
- Lakera Red prioritizes risks by impact and sets you up for runtime guardrails with Lakera Guard, per CRN.
- Giskard enables repeatable scenarios that catch logic regressions across updates, per vendor documentation.
-
Problem: Governance gaps around AI access controls and shadow AI increase breach impact, as highlighted by IBM’s 2025 report.
How each tool helps:- Group‑IB delivers artifacts and standards mapping that support governance committees and audits.
- PyRIT gives engineering teams measurable ASR baselines to track policy improvements, per Redmondmag.
- Lakera Red and Giskard supply repeatable test suites that can be wired into approvals before deployment, supported by references to OWASP categories (OWASP).
Bottom Line
AI red teaming has become a core security practice, not a specialized exercise reserved for mature teams. As LLM powered systems grow more autonomous and interconnected, the biggest risks come from interaction effects that only appear across multi-turn flows, tools, and external data sources. Effective programs combine automation with expert judgment, measure outcomes like attack success rate and regression drift, and map findings to recognized standards so results translate into governance decisions. If you want a low cost baseline, open source tooling is enough to catch obvious failure modes. If you need continuous coverage as prompts, models, and knowledge bases evolve, automated red teaming platforms make sense. For regulated environments or board level assurance, a standards aligned service engagement remains hard to replace. The common thread is simple: test continuously, measure objectively, and treat AI security the same way you treat production reliability, as an ongoing discipline rather than a one time review.


