Most teams discover their AI agents will happily click, spend, and send during a late-night incident review, not from a planned risk assessment. Working across different tech companies, we have seen three issues repeat: agents invoking tools out of scope, sensitive data leaking into prompts and logs, and no audit-grade evidence when something goes wrong.
The OWASP Top 10 for LLMs highlights prompt injection and data leakage as leading risks, and NIST's AI RMF calls for continuous, runtime controls, not just static policies (OWASP LLM Top 10 2025, NIST AI RMF 1.0).
Enterprise AI spend is accelerating, with worldwide AI spending forecast to reach 2.59 trillion dollars in 2026, which raises the cost of getting runtime controls wrong (Gartner AI spending forecast, May 2026). Four platforms consistently deliver inline enforcement for AI behaviors: Quantlix, Impart Security, Polaxis, and Safentic. In minutes, you will learn where each fits, what it costs, and how to deploy controls that block bad actions before they reach production.
Quantlix
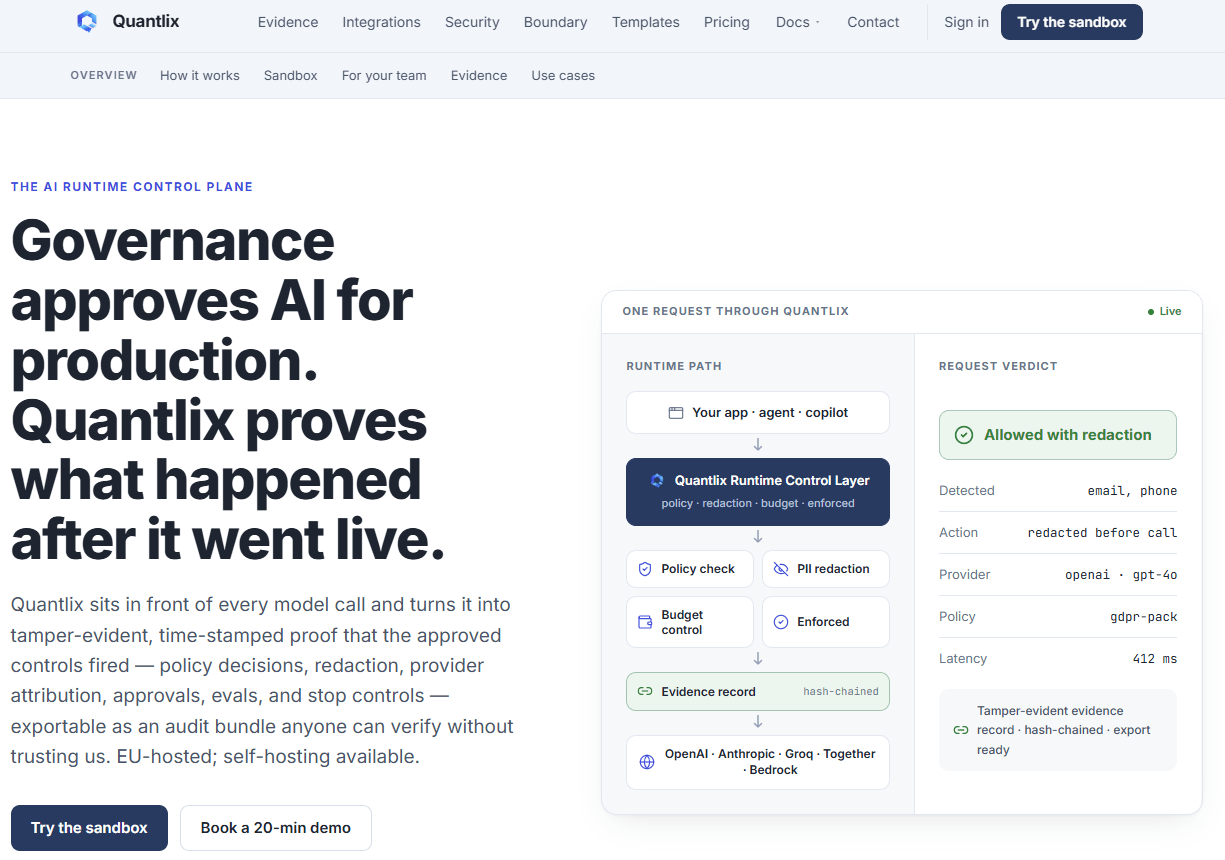
A runtime control plane that sits in front of every model call to enforce policy, redact sensitive data, control spend, and produce audit-grade evidence. According to vendor documentation, it records hash-chained traces and can export audit bundles.
- Best for: Teams that need audit-grade, tamper-evident traces for every AI request, plus redaction and spend controls.
- Key Features: Per Quantlix documentation, runtime policy enforcement, PII redaction and blocking before inference, budget and cost controls, hash-chained trace store with Rekor anchoring, exportable audit bundles.
- Why we like it: The evidence model is practical for audits. The focus on "allow, redact, block" before model invocation reduces downstream risk and token waste.
- Notable Limitations: EU-hosted footprint per vendor materials, which may not suit US-only data-residency needs. Newer product, so plan a proof of concept with synthetic attack traffic aligned to OWASP LLM risks (OWASP cheat sheet on prompt injection prevention).
- Pricing: Per the vendor's pricing page accessed on June 28, 2026: Builder free, Starter €9 per month, Growth €19 per month, Enterprise custom. Confirm enterprise terms directly. Pricing subject to change.
Impart Security (AI Runtime Defense)
A unified runtime enforcement engine that blocks AI, API, and web threats inline before they reach critical assets. The company announced AI Runtime Defense capabilities and funding expansions in 2025 to scale production deployments (Business Wire Series A, June 2025).
- Best for: Security teams that want one enforcement layer across LLMs, agent endpoints, MCP servers, APIs, and apps.
- Key Features: Per vendor documentation, inline request inspection, context and behavioral evaluation, unified enforcement for AI agents and traditional surfaces, bot defense announced in 2026 news (Business Wire product announcement, Feb 2026).
- Why we like it: Consolidates AI runtime controls with existing web and API defenses, which reduces policy sprawl and gives security operations one place to tune block rules.
- Notable Limitations: Limited third-party review coverage at the time of writing, for example, the G2 seller page lists zero reviews (G2 seller profile). Private-offer procurement and possible infrastructure charges apply in cloud marketplaces (AWS Marketplace listing notes on charges).
- Pricing: Available through AWS Marketplace under private offers, pricing not publicly listed. Contact Impart Security for a custom quote and check your AWS Marketplace terms.
Polaxis
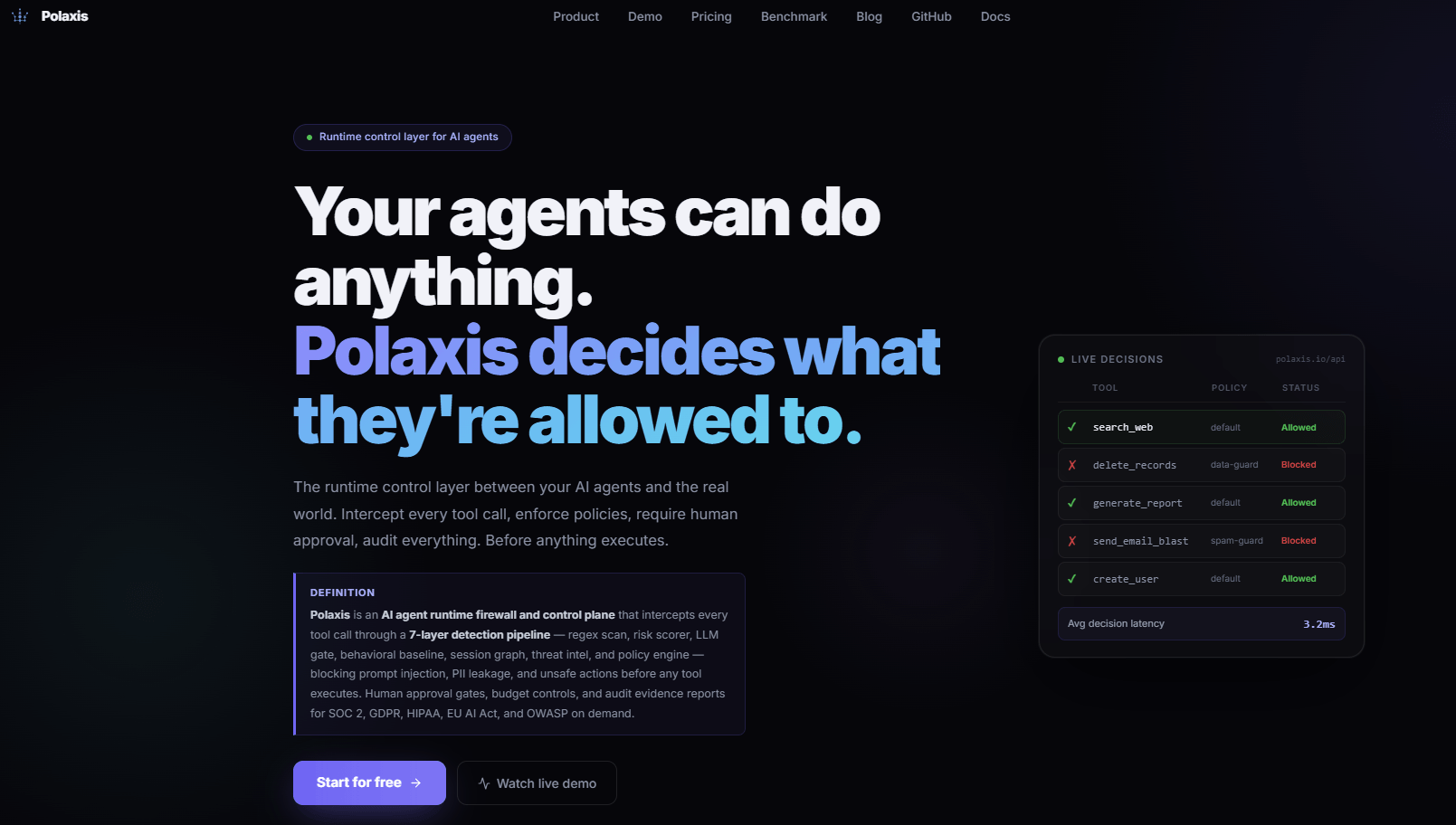
Middleware that intercepts AI agent tool calls with layered detection, approval gates, spend limits, and a full audit trail. According to vendor documentation, it targets agent frameworks like LangChain and CrewAI.
- Best for: Product and platform teams shipping autonomous or semi-autonomous agents that must be gated at the tool-call layer.
- Key Features: Per Polaxis documentation, seven-layer detection pipeline including regex scan, risk scoring, LLM verification, behavior baselining, session graph, threat intel, and policy engine. Human approval gating, budget enforcement, and detailed audit logging.
- Why we like it: Purpose-built for the "action boundary," where agents decide to execute tools. It adds the missing "are you allowed to do this now" checkpoint before anything runs.
- Notable Limitations: Early-stage packaging means policies and adapters may require tuning to avoid false positives, a known challenge in runtime enforcement (NIST AI RMF guidance on compensating and detective controls).
- Pricing: Per the vendor's public pricing page accessed on June 28, 2026: Free tier, Pro 149 dollars per month, Scale 499 dollars per month, Enterprise custom. Verify entitlements and any self-hosting options directly. Pricing subject to change.
Safentic
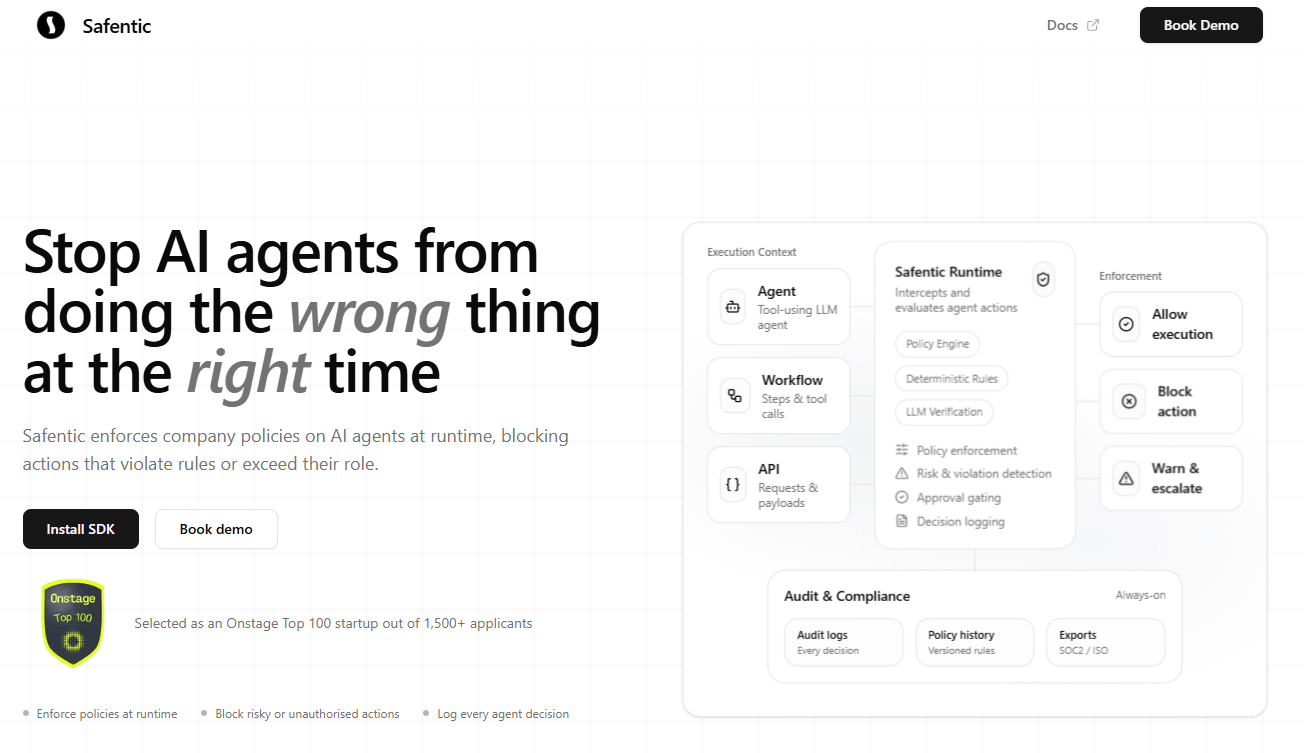
Runtime policy enforcement for AI agents with deterministic rules, LLM verification, approval gating, and decision logging. According to vendor documentation, it runs in the agent execution path and blocks unsafe actions.
- Best for: Engineering teams that prefer an SDK on top of existing agent stacks, with a policy-driven, review-before-execute model.
- Key Features: Per Safentic documentation, runtime policy engine, layered deterministic plus LLM verification, approval gates, always-on audit logs with policy history and exports.
- Why we like it: Fast path to gate risky actions without rewriting the agent. The YAML-style policy plus LLM verifier pattern maps cleanly to OWASP LLM risk scenarios.
- Notable Limitations: Pricing not publicly available at the time of writing. SDK integration still requires test coverage to reduce overblocking, which aligns with OWASP guidance to validate defenses against prompt injection and leakage (OWASP LLM Top 10 2025).
- Pricing: Pricing not publicly available. Contact Safentic for a custom quote.
Runtime AI Behavior Verification & Policy Enforcement Tools Comparison: Quick Overview
| Tool | Best For | Pricing Model | Highlights |
|---|---|---|---|
| Quantlix | Evidence-driven control plane with redaction and spend controls | Tiered subscription, enterprise custom | Tamper-evident traces, exportable audit bundles |
| Impart Security | Unified runtime defense across AI agents, APIs, and web apps | Private offer via cloud marketplace | Inline blocking across multiple surfaces |
| Polaxis | Agent tool-call interception with approval gates | Tiered subscription, enterprise custom | Seven-layer detection, spend limits, audit trail |
| Safentic | SDK approach for agent runtime policies and logs | Custom quote | Deterministic rules plus LLM verification, approval gating |
Runtime AI Behavior Verification & Policy Enforcement: Key Features at a Glance
| Tool | Feature 1 | Feature 2 | Feature 3 |
|---|---|---|---|
| Quantlix | Runtime policy enforcement | PII redaction before inference | Hash-chained evidence and audit exports |
| Impart Security | Inline threat blocking | Unified enforcement for AI, APIs, web | Bot defense updates in 2026 news |
| Polaxis | Layered detection on tool calls | Human-in-the-loop approvals | Budget and spend controls |
| Safentic | Deterministic plus LLM verification | Approval gating | Always-on decision logging and exports |
Runtime AI Behavior Verification & Policy Enforcement: Deployment Options
| Tool | Cloud API | On-Premise | Integration Complexity |
|---|---|---|---|
| Quantlix | Yes | Vendor materials indicate self-hosting options | Gateway placement in front of model calls |
| Impart Security | Yes, including marketplace routes | Yes, per enterprise deployments reported in news | Inline with AI, API, and web traffic |
| Polaxis | Yes | Self-hosting reported in enterprise tier | Agent middleware, wraps tool calls |
| Safentic | Yes, via SDK | Likely, given SDK model | Wrap existing agents, policy YAML |
Note: Where vendors do not publicly document a deployment model, treat it as unknown and confirm during procurement.
Runtime AI Behavior Verification & Policy Enforcement: Strategic Decision Framework
| Critical Question | Why It Matters | What to Evaluate | Red Flags |
|---|---|---|---|
| Can the platform block before execution, not after? | OWASP places prompt injection and data leakage among top risks, so prevention must happen inline | Pre-inference checks, tool-call gates, allow-redact-block outcomes | Alert-only designs with no enforcement path (OWASP LLM Top 10 2025) |
| Is there audit-grade evidence? | You need defensible records after incidents and for regulators | Trace integrity, tamper evidence, export formats | Opaque logs with no chain of custody or verification |
| How does it handle cost and abuse? | Attackers exploit agents and tools, while runaway prompts inflate cost | Spend limits, session awareness, blocking on abuse | No budget controls, no session context |
| Does it add acceptable latency? | Inline checks add overhead | p50 and p95 latency under attack and load | No published or testable latency claims |
| Can it evolve with threats? | Attackers adopt prompt injection variants rapidly | Policy testing, versioning, safe rollout | Manual edits only, no policy version control |
Runtime AI Behavior Verification & Policy Enforcement: Pricing & Capabilities Overview
| Organization Size | Recommended Setup | Monthly Cost | Annual Investment |
|---|---|---|---|
| Startup, 1-3 teams | Polaxis or Quantlix entry tiers for inline gates and evidence | Varies by tier, confirm current pricing | Varies by tier, confirm current pricing |
| Mid-market, multiple agents | Quantlix Growth or Polaxis Scale for volume and audit exports | Vendor tier pricing, subject to change | Request annual pricing and commit discounts |
| Enterprise, regulated | Quantlix Enterprise or Impart Security via marketplace for unified enforcement, plus Safentic SDK for specific stacks | Pricing not publicly available in most cases | Contact vendors for quotes, confirm SLAs and deployment scope |
Note: Pricing is frequently consumption-based or gated by volume and features. Where public pricing is absent, treat figures as unknown until quoted.
Problems & Solutions
-
Problem: Prompt injection and indirect prompt injection shift model behavior or drive tool misuse. This has been documented repeatedly by OWASP and major outlets covering real-world exploits in browsing and agent modes (OWASP LLM01:2025, The Guardian on AI browser injection, TechCrunch analysis).
- Quantlix: Applies allow, redact, or block before inference and records evidence, which helps contain injection attempts and prove actions taken, aligned with OWASP guidance.
- Impart Security: Evaluates and blocks threats inline across AI and web surfaces, which helps when injection traffic crosses channels.
- Polaxis: Intercepts agent tool calls with layered detection and approval gates, which is the right choke point for indirect injection that tries to trigger tools.
- Safentic: Combines deterministic rules with LLM verification, then gates execution, matching OWASP's call for defense-in-depth.
-
Problem: Sensitive data exposure through prompts and logs. OWASP flags training-data and prompt leakage as persistent risks, and regulators expect auditable controls (OWASP LLM Top 10 2025, NIST AI RMF 1.0).
- Quantlix: Performs PII redaction before the provider sees inputs and documents redaction events in the trace.
- Impart Security: Provides runtime enforcement with audit visibility across AI and APIs, which helps track and stop exfiltration paths.
- Polaxis: Can block or route to human approval when tool inputs include sensitive fields.
- Safentic: Policy rules and LLM verification prevent unsafe operations that would move or reveal sensitive data.
-
Problem: Attack speed and operational risk outpace manual reviews. Breach costs remain high, and adversaries move faster with AI, shrinking breakout times (IBM 2025 breach report, ITPro on accelerated breakout times).
- Quantlix: Automated budget enforcement and pre-inference checks reduce both risk and spend from malicious or runaway prompts.
- Impart Security: Inline blocking and bot defense help contain automated attacks quickly, not after alerts fire.
- Polaxis: Approval gates let humans review only high-risk actions, keeping latency low for safe paths.
- Safentic: SDK placement lets teams insert gates where they already orchestrate agents, which accelerates rollout.
The Bottom Line
If your agents can act, you need runtime enforcement that blocks, redacts, and logs before execution, not after the incident review. OWASP's LLM risk work and NIST's AI RMF agree that dynamic controls and continuous monitoring are now table stakes (OWASP LLM Top 10 2025, NIST AI RMF 1.0).
Quantlix stands out for audit-grade evidence, Impart Security for unified enforcement across AI and traditional surfaces, Polaxis for agent tool-call control with approvals, and Safentic for a fast SDK path. Start with a two-week lab that replays OWASP LLM injection cases, measure false positives and latency, then roll out to production behind spend caps and human-approval gates.


