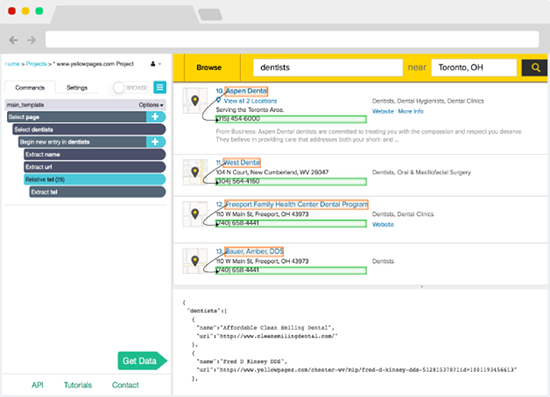
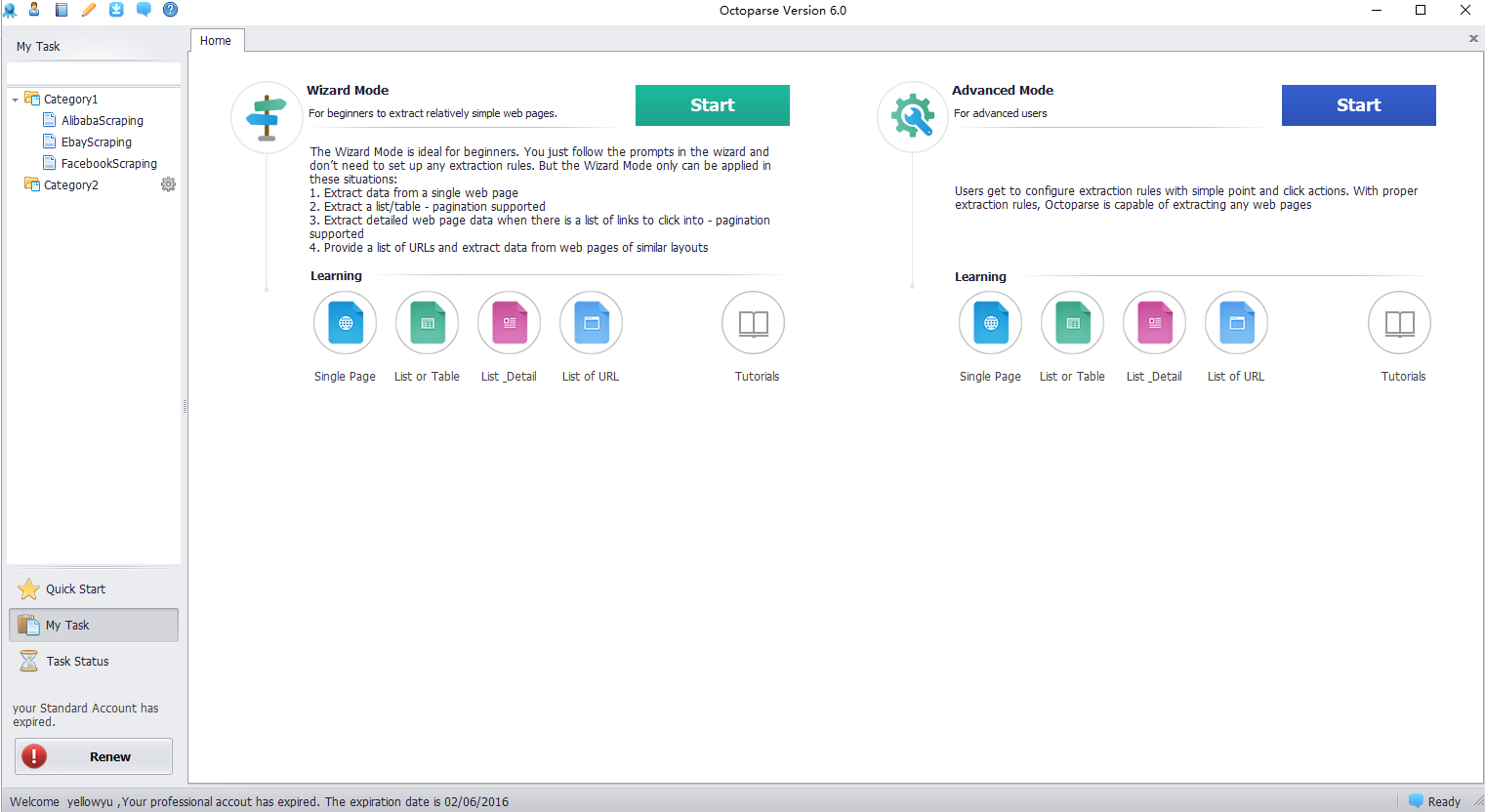
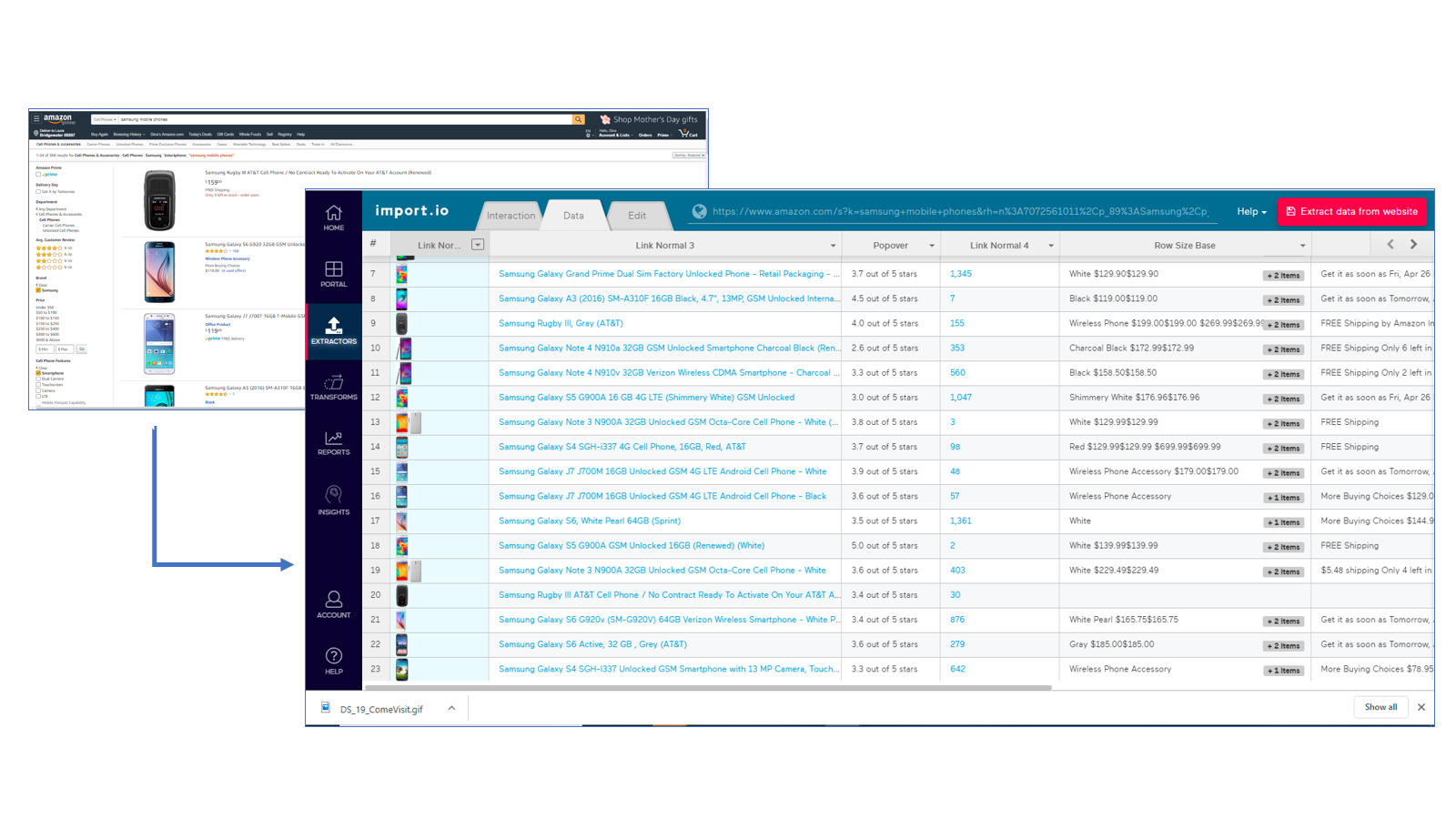
Webharvy is a browser extension that makes web scraping as easy as clicking a button. In other words, it's designed for people who aren't computer programmers.
WebHarvy is able to automatically deduce data patterns from webpages. To scrape a list of things (name, address, email, price, etc.) from a web page, no additional setting is required. By connecting to target websites over a proxy server or virtual private network (VPN), you can scrape anonymously and circumvent web servers' bans on web scraping software.
There are a bunch of decent tools out there that offer the same array of services as Webharvy. And it can sure get confusing to choose the best from the lot. Luckily, we've got you covered with our curated lists of alternative tools to suit your unique work needs, complete with features and pricing.